
Learning Objectives
Following this assignment students should be able to:
- import, view properties, and plot a
raster- perform simple
rastermath- extract points from a
rasterusing a shapefile- evaluate a time series of
raster
Reading
-
Topics
raster- Raster math
- Plotting spatial images
- Shapefile import
- Integrate
rasterandvectordata
-
Readings
-
Additional information
Lecture Notes
Exercises
Canopy Height from Space (30 pts)
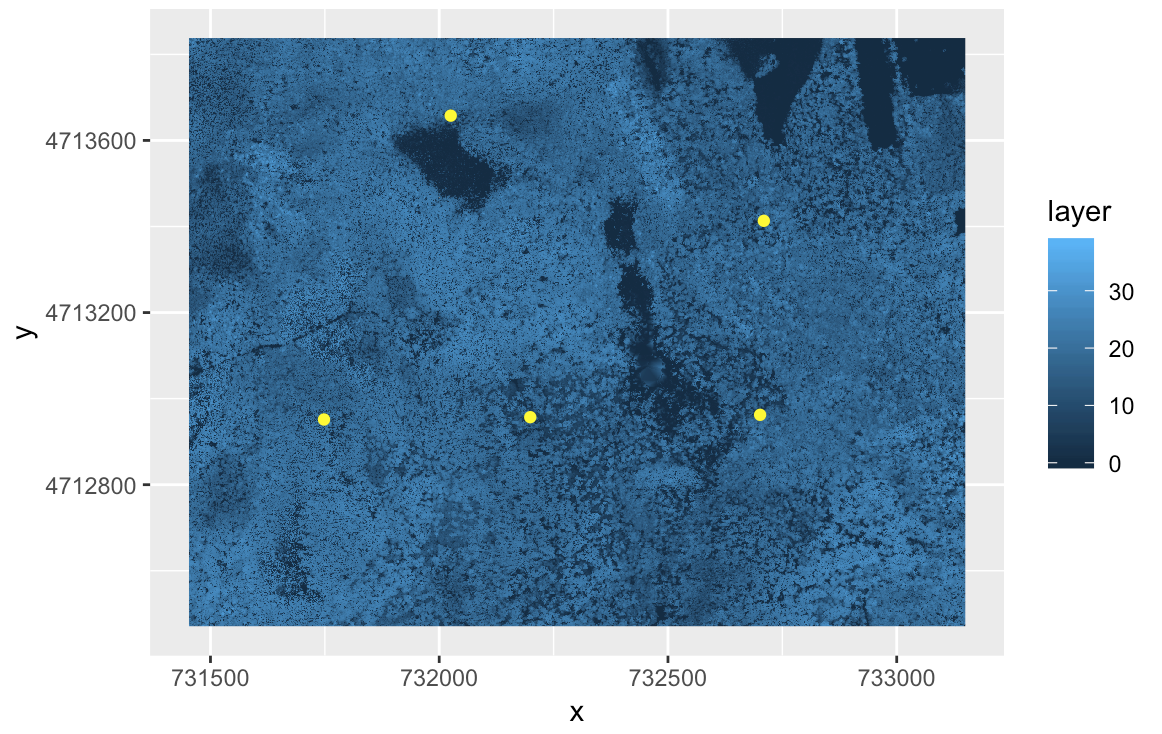
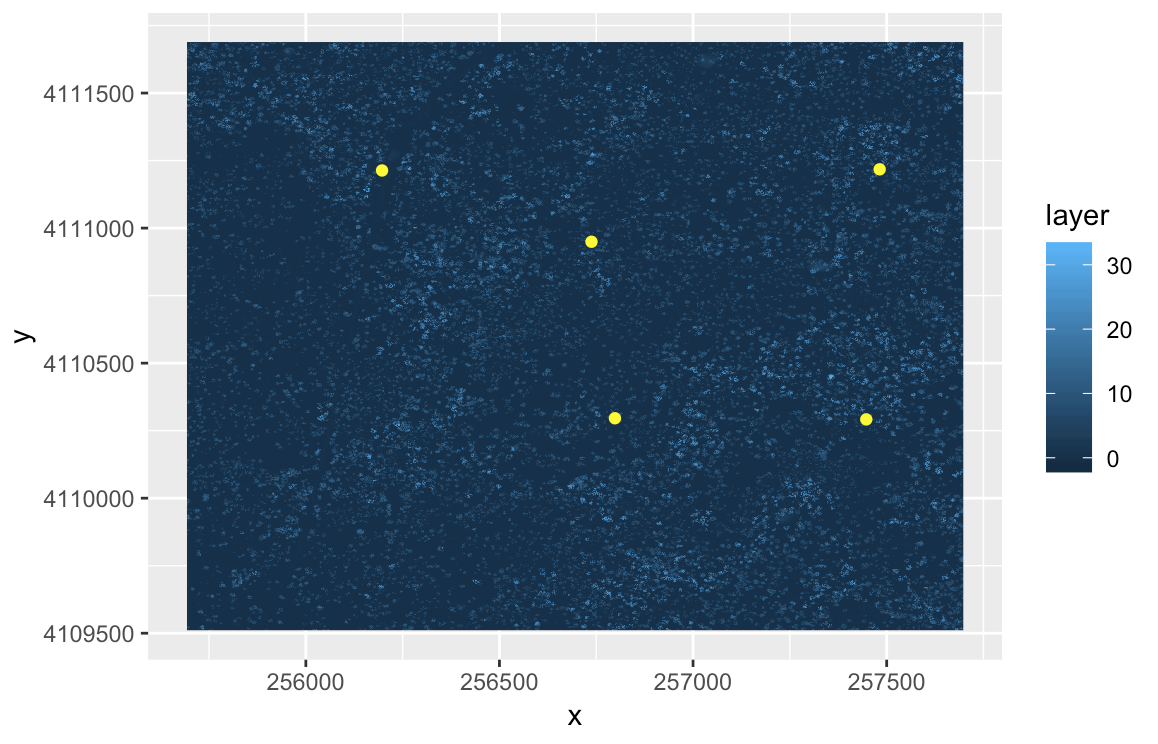
The National Ecological Observatory Network has invested in high-resolution airborne imaging of their field sites. Elevation models generated from LiDAR can be used to map the topography and vegetation structure at the sites. This data gets really powerful when you can compare ecological processes across sites. Download the elevation models for the Harvard Forest (
HARV) and San Joaquin Experimental Range (SJER) and the plot locations for each of these sites. Often, plots within a site are used as representative samples of the larger site and act as reference areas to obtain more detailed information and ensure accuracy of satellite imagery (i.e., ground truth).-
Create two Canopy Height Models using simple
rastermath (chm = dsm - dtm), one for theHARVsite (which was done during the lecture) and another for theSJERsite. -
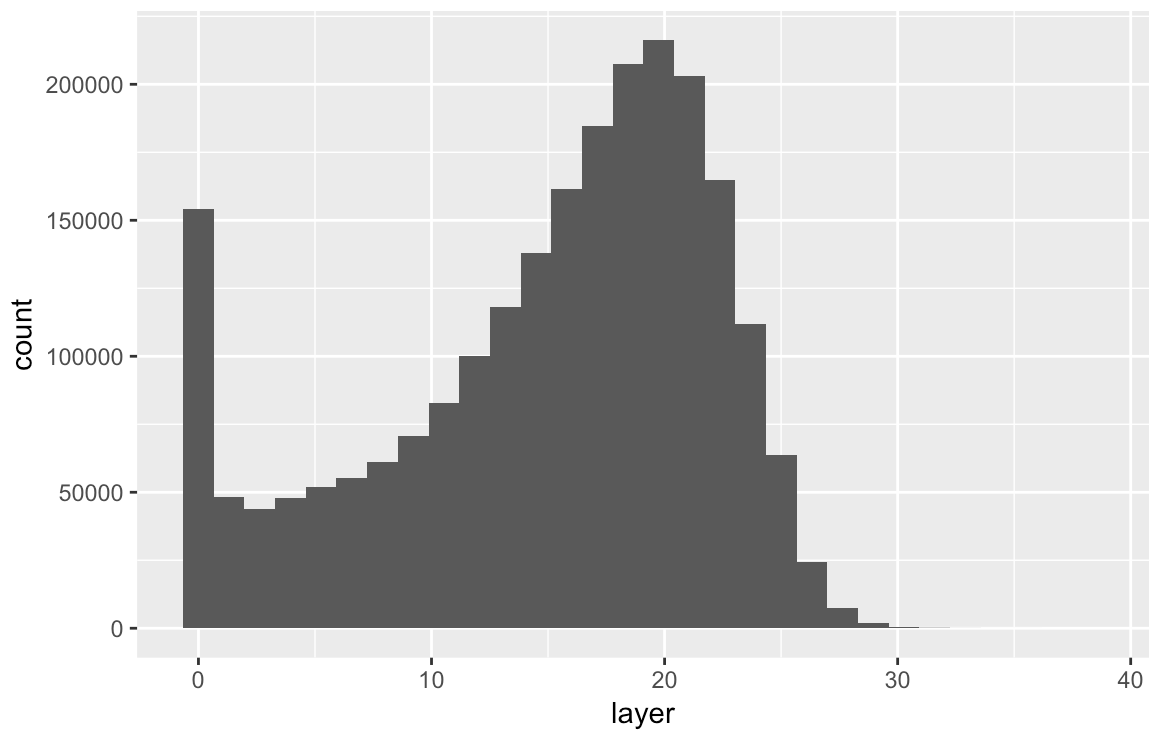
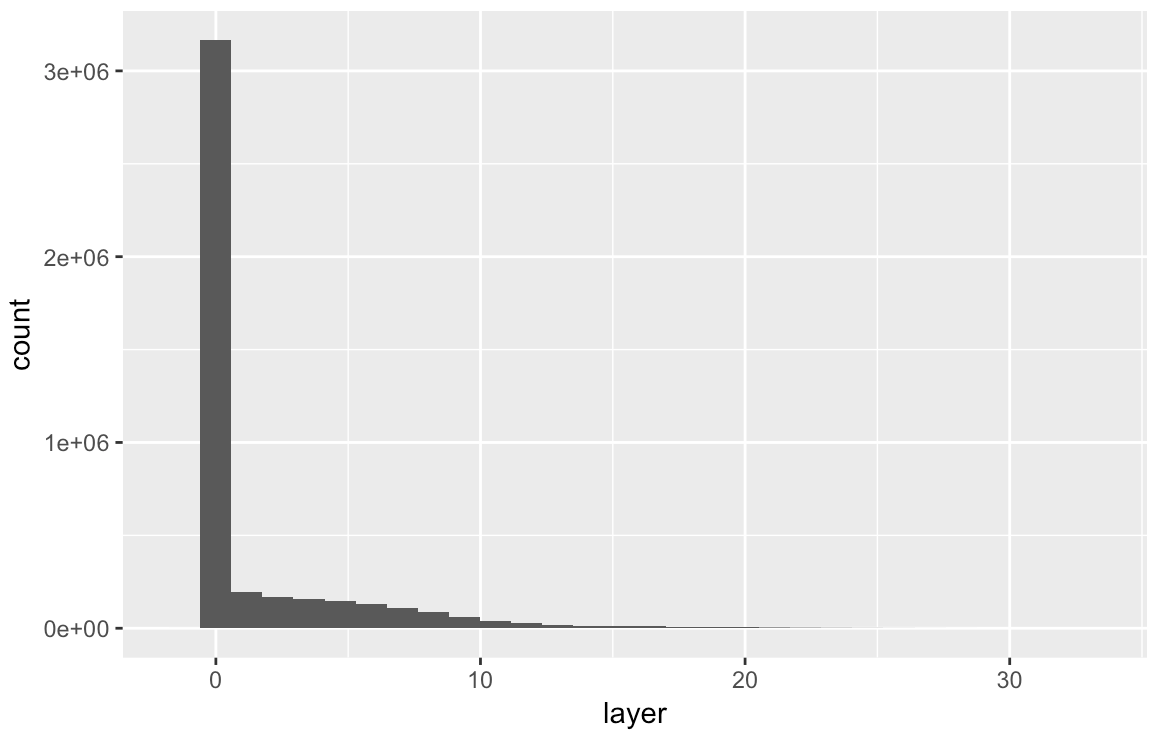
Create plots and histograms of canopy heights for both of the sites using
ggplot. -
Add corresponding points from
plot_locationsfolder to each site plot. -
Create a single dataframe with two columns, one of the maximum canopy heights for each point at the
HARVsite and one for theSJERpoints’ maximum canopy heights. When extracting the canopy height values, use a buffer of 10.
-
Phenology from Space (40 pts)
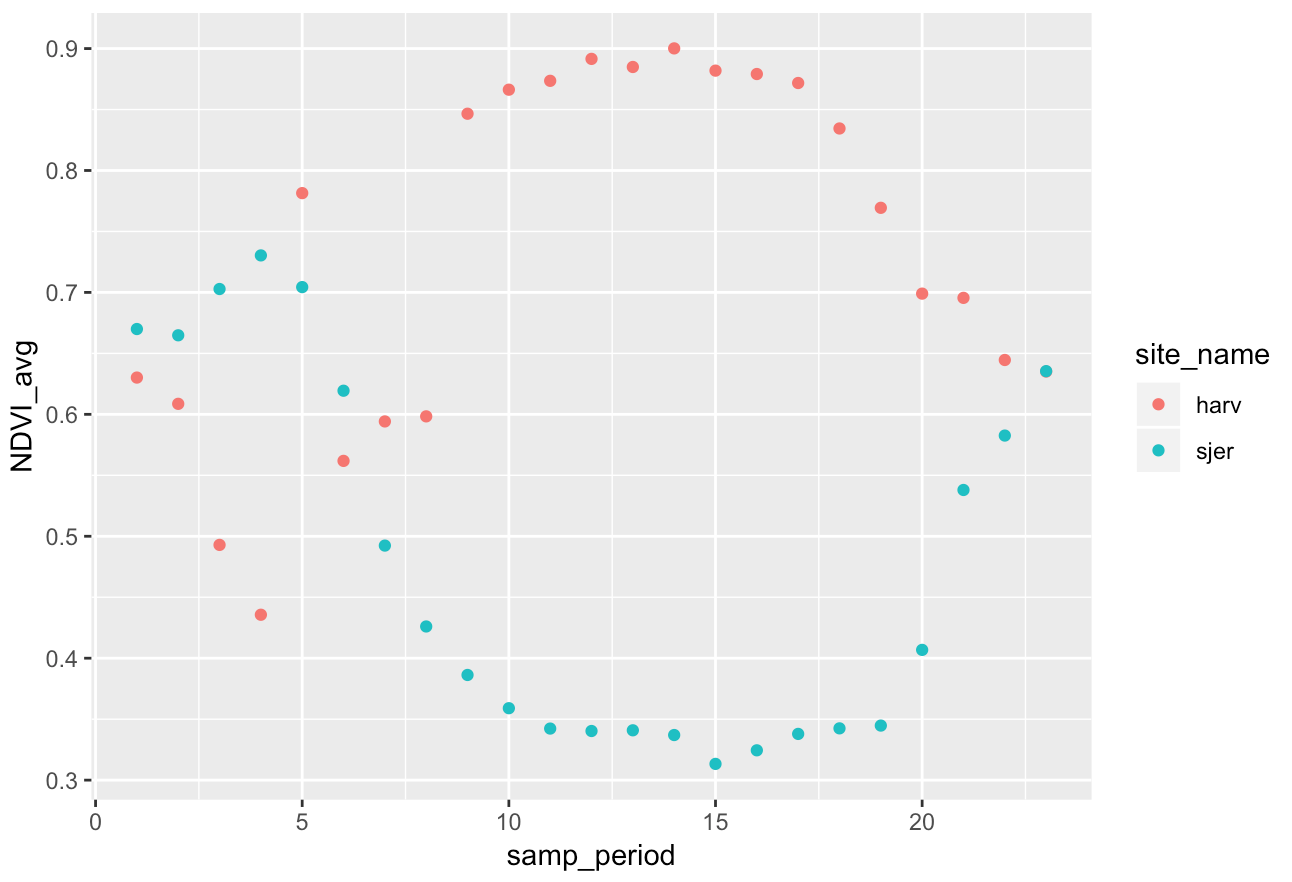
The high-resolution images from Canopy Height from Space can be integrated with satellite imagery that is gathered more frequently. We will use data collected from MODIS. One common ecological process that can be observed from space is phenology (or seasonal patterns) of plants. Multi-band satellite imagery can be processed to provide a vegetation index of greenness called NDVI. NDVI values range from
-1.0to1.0, where negative values indicate clouds, snow, and water; bare soil returns values from0.1to0.2; and green vegetation returns values greater than0.3.Download HARV_NDVI and SJER_NDVI and place them in a folder with the NEON airborne data. The
zipcontains folders with a year’s worth of NDVI sampling from MODIS. The files are in order (and named) by date and can be organized implicitly by sampling period for analysis.- Plot the whole-raster mean NDVI (
cellStats()) for Harvard Forest and SJER through time using different colors for the two sites. To do this:- Load the files for each site as a raster stack
- Use
cellStats()to calculate the mean values for each raster in the stack. Call the outputsharv_avgandsjer_avg - Create a vector of sampling periods for each site: e.g.,
samp_period = c(1:length(harv_avg), 1:length(sjer_avg)) - Create a vector of site names for each site: e.g.,
site_name = c(rep("harv", length(harv_avg)), rep("sjer", length(sjer_avg))) - Make a data frame that includes columns for site name, sampling period, and the average NDVI values (concatenate the two vectors using
c()). - Graph the trends through time using
ggplot
- Extract the NDVI values from all rasters for the
HARV_plotsandSJER_plotsinNEON-airborne/plot_locations. Runningextract()on a raster stack results in a matrix with one column per raster and one row per point. To more easily work with this data, we want to have one column with the raster names and one column per point, which you can do by transposing the matrix with thet()function. Then make this into a dataframe and turn the rownames into a column usingtibble::rownames_to_column(your_matrix, var = "date"). Do this for bothHARVandSJER.
- Plot the whole-raster mean NDVI (
Species Occurrences Map (30 pts)
A colleague of yours is working on a project on banner-tailed kangaroo rats (Dipodomys spectabilis) and is interested in what elevations these mice tend to occupy in the continental United States. You offer to help them out by getting some coordinates for specimens of this species and looking up the elevation of these coordinates.
-
Get banner-tailed kangaroo rat occurrences from GBIF, the Global Biodiversity Information Facility, using the
spoccR package, which is designed to retrieve species occurrence data from various openly available data resources. Use the following code to do so:dipo_df = occ(query = "Dipodomys spectabilis", from = "gbif", limit = 1000, has_coords = TRUE) dipo_df = data.frame(dipo_df$gbif$data) - Clean up the data by:
- Using the
renamefunction fromdplyrto rename the second and third columns of this dataset tolongitudeandlatitude - Filter the data to only include those specimens with
Dipodomys_spectabilis.basisOfRecordthat isPRESERVED_SPECIMENand aDipodomys_spectabilis.countryCodethat isUS - Remove points with values of
0forlatitudeorlongitude - Remove all of the columns from the dataset except
latitudeandlongitudeusingselect - Use
head()function to show the top few rows of this cleaned dataset
- Using the
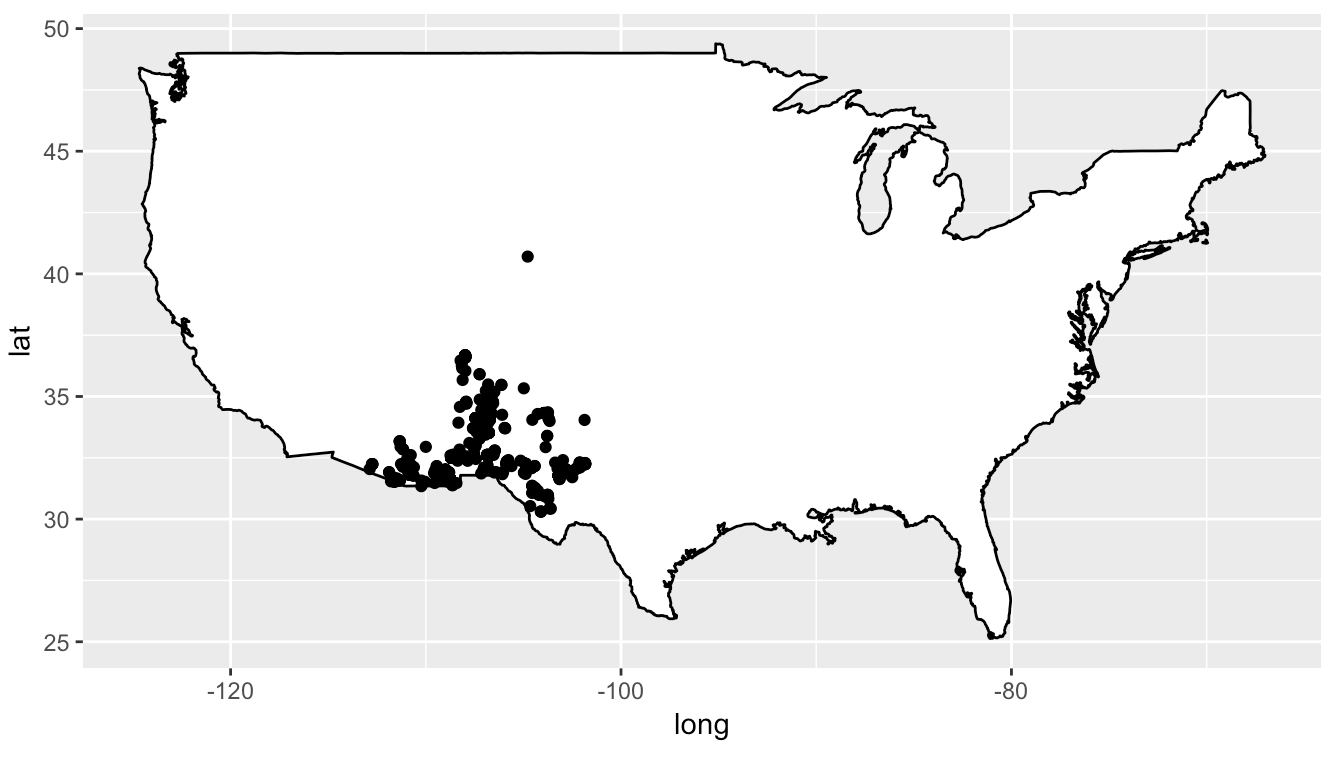
- Do the following to display the locations of these points on a map of the United States:
- Get data for a US map using
usmap = map_data("usa") - Plot it using
geom_polygon. In the aesthetic usegroup = groupto avoid weird lines cross your graph. Usefill = "white"andcolor = "black". - Plot the kangaroo rat locations
- Use
coord_quickmap()to automatically use a reasonable spatial projection
- Get data for a US map using
-
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}