
Major question
- How can I combine existing commands to do new things?
Major Objectives
- Redirect a command’s output to a file.
- Process a file instead of keyboard input using redirection.
- Construct command pipelines with two or more stages.
- Explain what usually happens if a program or pipeline isn’t given any input to process.
- Explain Unix’s ‘small pieces, loosely joined’ philosophy.
We’ll get back to Nelle’s journey soon, but now that we know a few basic commands, we can finally look at the shell’s most powerful feature: the ease with which it lets us combine existing programs in new ways.
We start with a directory called molecules
that contains six files describing some simple organic molecules.
The .pdb extension indicates that these files are in Protein Data Bank format,
a simple text format that specifies the type and position of each atom in the molecule.
$ ls molecules
cubane.pdb ethane.pdb methane.pdb
octane.pdb pentane.pdb propane.pdb
Let’s go into that directory with cd molecules and run the
command wc *.pdb.
wc is the “word count” command:
it counts the number of lines, words, and characters in files
(from left to right, in that order). It then prints them out
with totals at the end.
The * in *.pdb matches zero or more characters,
so the shell turns *.pdb into a list of all .pdb files in the current directory:
$ cd molecules
$ wc *.pdb
20 156 1158 cubane.pdb
12 84 622 ethane.pdb
9 57 422 methane.pdb
30 246 1828 octane.pdb
21 165 1226 pentane.pdb
15 111 825 propane.pdb
107 819 6081 total
If we run wc -l instead of just wc,
the output shows only the number of lines per file:
$ wc -l *.pdb
20 cubane.pdb
12 ethane.pdb
9 methane.pdb
30 octane.pdb
21 pentane.pdb
15 propane.pdb
107 total
We can also use -w to get only the number of words,
or -c to get only the number of characters.
Which of these files contains the fewest lines? It’s an easy question to answer when there are only six files, but what if there were 6000? Our first step toward a solution is to run the command:
$ wc -l *.pdb > lengths.txt
Using redirects
The greater than symbol, >, tells the shell to redirect the command’s output
to a file instead of printing it to the screen. (This is why there is no screen output:
everything that wc would have printed has gone into the
file lengths.txt instead.) The shell will create
the file if it doesn’t exist. A word of caution: If the file exists, it will be
silently overwritten, which may lead to data loss!!!
The command ls lengths.txt confirms that the file exists:
$ ls lengths.txt
lengths.txt
Using cat to view file contents
We can now send the content of lengths.txt to the screen using cat lengths.txt.
cat stands for “concatenate” and
it outputs (prints) the contents of files one after another.
There’s only one file in this case,
so cat just shows us what it contains:
$ cat lengths.txt
20 cubane.pdb
12 ethane.pdb
9 methane.pdb
30 octane.pdb
21 pentane.pdb
15 propane.pdb
107 total
Note that the total line is included in the file,
because it was output by the wc -l command!
Using less for Page by Page Output
We’ll continue to use cat in this lesson, for convenience and consistency,
but it has the disadvantage that it always dumps the whole file onto your screen.
If we had 50,000 .pdb files, and counted all their lengths, the
lengths.txt file would be very long! More useful in practice
is the command less,
which is used like: less lengths.txt.
This displays one screenful of the file, and then stops.
But you will notice that you are still running inside the less command!
While running less there are lots of things you can do that we
won’t cover right now, but remember it’s very useful for big
text-based files. You can go forward one screenful by pressing the
spacebar,
or back one by pressing b. To exit the less command you
must press q to quit.
Using sort
Not surprisingly, the sort command sorts elements in a file.
The default for sort is to use alphanumerical order.
This is important to know when working with numbers.
While we are still in the molecules directory,
create a file numbers.txt and enter the following numbers:
10
2
19
22
6
If we run sort on this file
the output is slightly different because it’s sorted in alphanumerical order:
10
19
2
22
6
If we run sort -n on the same input, we get this instead:
2
6
10
19
22
The -n flag specifies a numerical rather than an alphanumerical sort.
It’s also important to know that using sort does not change the file;
instead, it outputs the sorted result to the screen.
Now let’s use the sort command to sort the contents of lengths.txt.
$ sort -n lengths.txt
9 methane.pdb
12 ethane.pdb
15 propane.pdb
20 cubane.pdb
21 pentane.pdb
30 octane.pdb
107 total
We can put a permanent sorted list of lines in another file called sorted-lengths.txt
by redirecting the output using > sorted-lengths.txt after sort,
just as we used > lengths.txt to put the output of wc into lengths.txt.
Once we’ve done that,
we can run the head command to output the first few lines of sorted-lengths.txt. Let’s just look at the top line using head -n 1:
$ sort -n lengths.txt > sorted-lengths.txt
$ head -n 1 sorted-lengths.txt
9 methane.pdb
Remember that using -n 1 tells the head command
we only want the first line of the file;
-n 20 would get the first 20,
and so on.
Since sorted-lengths.txt contains the lengths of our files in
numerical order (i.e. from least to greatest),
the output of head must be the file with the fewest lines.
Always redirect output to a different filename
While working with files it’s almost always a very bad idea to redirect a command’s output to the same file. For example:
$ sort -n lengths.txt > lengths.txt
Although sort doesn’t change the file when the output
goes to the terminal, if you redirect the output to a file,
the file has the new sorted structure. If you redirect a file to
the same filename, it will overwrite (the same as deleting)
the original contents of lengths.txt! Little things like this
may cause incorrect results later.
Using echo and Another Redirect: >> to Append
We have seen the use of >, but there is a similar operator >>
which works slightly differently.
We’ll use the echo command to help understand the difference between > and >>.
The echo command outputs what you give it. For example:
$ echo hello
hello
$ echo what a crazy command!
what a crazy command!
You can also redirect the output of echo to a file:
$ echo hello > hello.txt
$ cat hello.txt
hello
By using the echo command to output some text, run each of the commands below
twice (consecutively) to reveal the difference between the two operators > and >>:
$ echo hello > testfile01.txt
and:
$ echo hello >> testfile02.txt
Hint: After executing each command twice in a row, examine the output files.
In the first example with >, the string “hello” is written to testfile01.txt,
but the file gets overwritten each time we run the command.
We see from the second example that the >> operator also writes “hello” to a file
(in this casetestfile02.txt),
but appends the string to the file when the file already exists (i.e. when we run it for the second time).
Appending Data
We have already met the head command, which prints lines from the start of a file.
The tail command is similar, but prints lines from the end of a file instead.
So tail is very useful when working with “appending” outputs to a new file.
Consider the file data-shell/data/animals.txt. First we can check how
many lines are in the file:
cd data
wc -l animals.txt
8 animals.txt
After the following commands, select the answer that
corresponds to the file animalsUpd.txt:
$ head -n 3 animals.txt > animalsUpd.txt
$ tail -n 2 animals.txt >> animalsUpd.txt
- The first three lines of
animals.txt - The last two lines of
animals.txt - The first three lines and the last two lines of
animals.txt - The second and third lines of
animals.txt
Solution
Option 3 is correct.
For option 1 to be correct we would only run the head command.
For option 2 to be correct we would only run the tail command.
For option 4 to be correct we would have to pipe the output of
head into tail by doing head -n 3 animals.txt | tail -n 2 > animalsUpd.txt
If you think this is confusing, it’s okay at this point!
Even once you understand what wc, sort, and head do,
all those intermediate files make it hard to follow what’s going on.
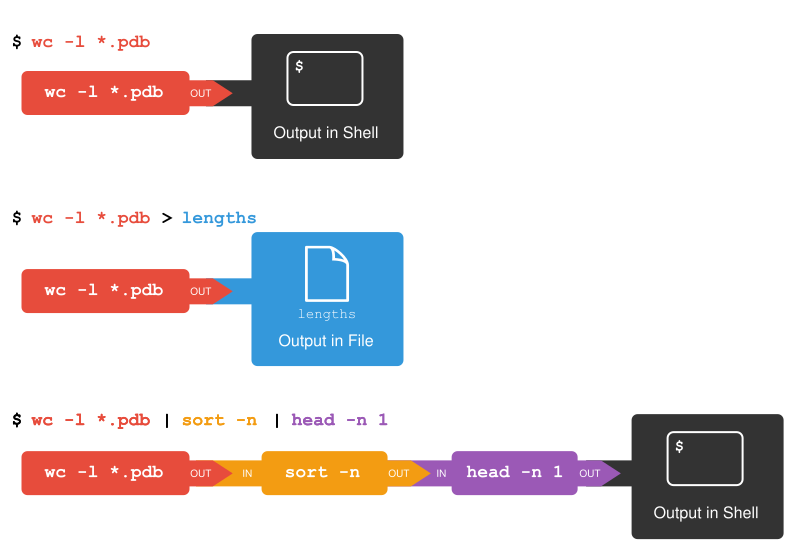
Using Pipes |
We can make working with these commands and files a little
easier to understand by (for example) running sort and head together
using a “pipe” (a vertical bar symbol ”|”):
First, change back into the molecules directory:
$ cd ../molecules
$ sort -n lengths.txt | head -n 1
9 methane.pdb
The vertical bar, |, or pipe between the two commands
tells the shell that we want to use
the output of the command on the left
as the input to the command on the right.
AND, nothing prevents us from chaining more pipes together.
For example, we can send the output of wc directly to sort,
and then the resulting output to head.
First use a pipe to send the output of wc to sort:
$ wc -l *.pdb | sort -n
9 methane.pdb
12 ethane.pdb
15 propane.pdb
20 cubane.pdb
21 pentane.pdb
30 octane.pdb
107 total
Then add another pipe, to the head command,
so that the full pipeline becomes:
$ wc -l *.pdb | sort -n | head -n 1
9 methane.pdb
This is similar to nesting functions in math like log(3x)
First you calculate the
3 times x, then you calculate the log of 3x.
In our case, the calculation is “sort the line counts
of *.pdb, and show the top line” (the smallest file).
Also, note that we haven’t changed any files at all… we have pulled out exactly the information we wanted!! Thought Question: How can we get the biggest file?
The pipe character | is very important in Bash scripting, and
we will use pipes often to feed the standard output from one process to
the standard input of another.
Computational vocabulary: stdin, stdout, stderr
Pipes take advantage of how computers work. When a computer runs a program — any program — it “loads the software” into memory, where the software is now called a process. Every process has a standard input usually referred to as “stdin”, and a default output called standard output (or “stdout”). There is a second available output called standard error (“stderr”) that is typically used for error or diagnostic messages.
The shell is a program that normally takes what we type on the keyboard as its standard input, and whatever it produces as standard output is displayed on our screen.
We redirect the standard output when we use the > symbol
for example: wc -l *.pdb > lengths.txt.
The shell creates a process for the wc program, and
uses the filenames as arguments for standard input,
then uses > to redirect standard output to a specified file.
If we run wc -l *.pdb | sort -n instead,
the shell creates two processes
(one for each process in the pipe).
The standard output of wc is fed directly to the standard input of sort;
and sort’s output goes to the screen.
And if we run wc -l *.pdb | sort -n | head -n 1,
we get three processes with data flowing from the files,
through wc to sort,
and from sort through head to the screen.
This simple idea is why Unix has been so successful, and why we are
learning how to use Unix and Unix-based programming languages.
Instead of creating enormous programs that try to do many different things,
Unix programmers focus on creating lots of simple tools that each do one job well,
and that work well with each other.
This programming model is called “pipes and filters”.
We’ve already seen pipes;
and a filter is a program like wc or sort
that transforms a stream of input into a stream of output.
Almost all of the standard Unix tools can work this way.
Redirecting Input
As well as using > to redirect a program’s output, we can use < to
redirect its input, i.e., to read from a file instead
of from standard input. For example, instead of writing
wc ammonia.pdb, we could write
wc < ammonia.pdb. In the first case, wc gets a command line
argument telling it what file to open. In the second, wc doesn’t have
any command line arguments, so it reads from standard input, but we
have told the shell to send the contents of ammonia.pdb to wc’s
standard input.
Clarifying: What Does
<Mean?Change directory to
data-shell(the top level of our downloaded example data). Remember you can always use:cd ~/Desktop/data-shellLet’s examine the difference between:
$ wc -l notes.txtand:
$ wc -l < notes.txtSolution
<is used “to redirect input to a command”.Notice that in both examples, the shell returns the number of lines from the input to the
wccommand. However in the first example, the input is the filenotes.txtand so the file name is given in the output from thewccommand. In the second example, the only the contents of the filenotes.txtare redirected to standard input. Hence the file name is not given in the output - just the number of lines.This is similar to entering the contents of a file by typing at the prompt. Try this for yourself:
$ wc -l this is a testCtrl-D (This tells the shell you finished typing the input). The shell then executes the
wc -lcommand using your input lines (no file needed!).3
The uniq Command Removes Adjacent Duplicates
The command uniq removes adjacent duplicated lines from its input.
For example, look at the contents of the file data-shell/data/salmon.txt:
$ cat data/salmon.txt
coho
coho
steelhead
coho
steelhead
steelhead
Running the command uniq salmon.txt from the data-shell/data directory produces:
$ uniq data/salmon.txt
coho
steelhead
coho
steelhead
uniq only removes adjacent duplicated lines because in
very large data sets, it would not be uncommon to have a line
entered twice. This would be hard to find without uniq.
What other command could
you combine with it in a pipe to remove all duplicated lines?
Solution Hint
What’s the output of:
$ sort salmon.txt | uniq
Pipe Construction and the cut command
Look at the file animals.txt in the data-shell/data folder,
$ cat animals.txt
2012-11-05,deer
2012-11-05,rabbit
2012-11-05,raccoon
2012-11-06,rabbit
2012-11-06,deer
2012-11-06,fox
2012-11-07,rabbit
2012-11-07,bear
Type in the following command:
$ cut -d , -f 2 animals.txt
The cut command separates columns of data, and the -d flag
designates the column delimiter for each line to be a
“comma” , and the -f 2 flag tells cut to print the
second field in each line, to give the following output:
deer
rabbit
raccoon
rabbit
deer
fox
rabbit
bear
Build a Pipeline
While your current directory is data-shell/data/
build a pipeline to produce a table that shows
the total count of each type of animal in the file?
$ cut -d , -f 2 animals.txt
deer
rabbit
raccoon
rabbit
deer
fox
rabbit
bear
$ cut -d , -f 2 animals.txt | sort
bear
deer
deer
fox
rabbit
rabbit
rabbit
raccoon
$ cut -d , -f 2 animals.txt | sort | uniq -c
1 bear
2 deer
1 fox
3 rabbit
1 raccoon
Congratulations, you are well on the way to understanding how to build pipelines in the Shell!
Keypoints to Learn
catdisplays the contents of its inputs.headdisplays the first 10 lines of its input.taildisplays the last 10 lines of its input.sortsorts its inputs.wccounts lines, words, and characters in its inputs.command > fileredirects a command’s output to a file (overwriting any existing content).command >> fileappends a command’s output to a file.<operator redirects input to a commandfirst | secondis a pipeline: the output of the first command is used as the input to the second.- The best way to use the shell is to use pipes to combine simple single-purpose programs (filters).